Cloud systems | Renewable Energy | Regional Climate - Dwaipayan Chatterjee
The 21st century grapples with crucial challenges—transitioning to renewable energy and combating climate change. A responsible society anticipates sustainable solutions for both. Another term in the discourse is Artificial Intelligence (AI), with considerable speculation. Delving into all three areas, Dwaipayan Chatterjee, while working in Prof. Crewell’s AWARES team, uncovered significant potential for future interdisciplinary research.
Cloud systems, crucial for solar energy, modulate the solar radiation budget. They impact heat and moisture distribution in climate change. However, uncertainties persist about their physical properties and connections at different scales.
Satellites capture cloud patterns, but labeling for traditional neural networks is challenging. From an AI perspective, my research prioritizes unlabeled learning, allowing the neural network learns to from scratch. This open up understanding the underlying representation of satellite observations and allows extracting features for a data-driven comprehension of regional climate and its application in solar energy production.
Classification by the self-supervised deep neural network at k = 7 for 128 x 128 configuration. Thirty random samples were selected over central Europe and visualized for each class. Each image is assigned a unique class through a colored frame. The bar charts in the lower part of a) and b) represent the number of images in relative percentage and cloud fraction in each regime. To better associate the class number with the cloud regime, the centroid image is shown as well.
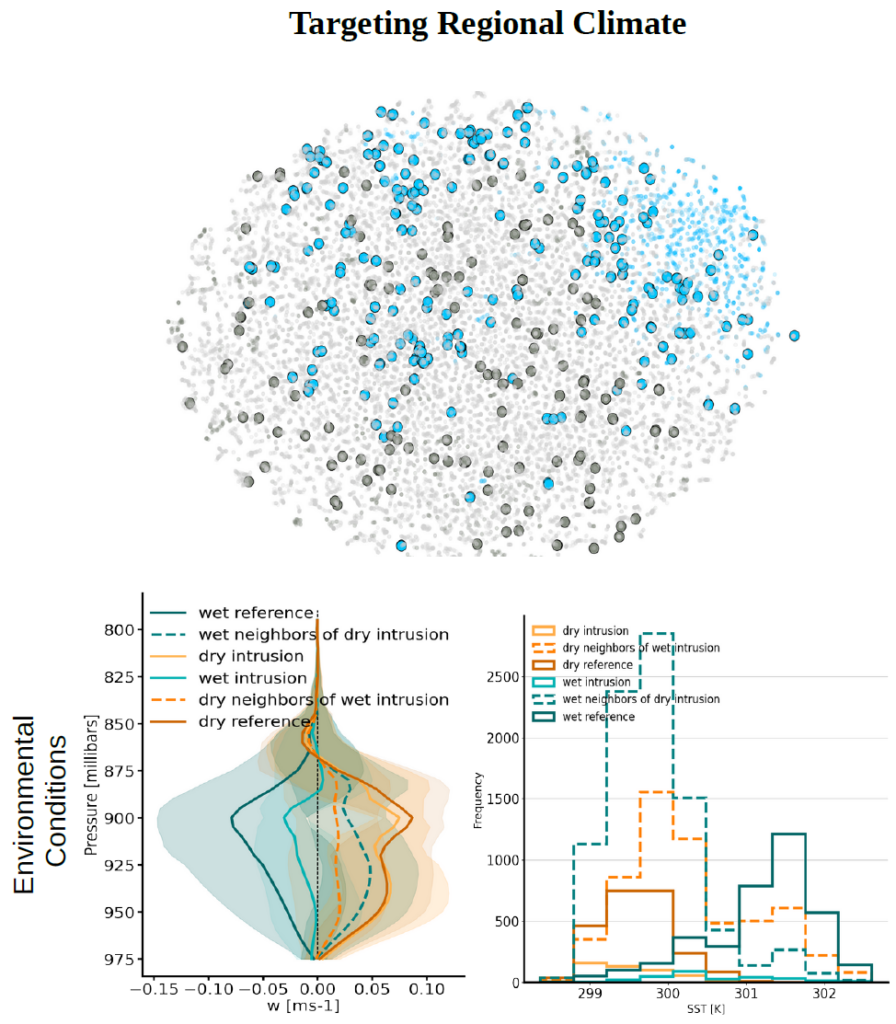
Feature space with wet-dry conditions defined based on 80/20th percentile of integrated water vapor and w-500 wind speed from ERA-5. Grey defines dry conditions, blue is wet conditions, and light grey is the intermediate state, dry/wet intrusion as decided based on the 30 nearest neighbors. Average profiles of vertical wind speed W, and sea surface temperature (SST) for the reference states, intrusions, and their 30 nearest opposite neighbors.
Anthropogenic land use has a huge impact on (vegetational) ecology, mostly with a negative effect on plant health and development. However, there is also an increasing effort to protect naturalness by protecting areas and managing them to slow down climate change, conserve local biodiversity, and retain habitats. Therefore, mapping naturalness and human influence is an important task and we developed a machine learning technique to do so. Neural networks consist of neurons that are activated during calculation. These activations can be analyzed to understand the decision process of the neural network. We have evaluated their connection to natural and anthropogenic characteristics in landscapes and established a linkage between activations and attributions. An attribution describes the effect an activation has on the model’s prediction. Our method allows us to recognize complex patterns in unseen test data and evaluate their influence on the model’s decision. Harmonizing the attributions, large-scale scenes and scenes at different points in time become comparable and can be evaluated (Stomberg et al., 2023). We further invented a neural network architecture that allows us to get high-level features with the resolution of the input image. With standard convolutional neural network architectures the user has to decide between resolution and complexity of the features when applying attribution methods.
From left to right: (1) For demonstration, the satellite image has been split into four separate images. (2) An attribution method applied to the input layer gives rarely meaningful results. (3) Applied to the last convolutional layer, the result is meaningful, however, the resolution is low. (4) With our neural network architecture, we generate meaningful attributions in high-resolution. (5) Harmonizing these attributions, all images become comparable. (6) Data not well represented in the training data can be grayed out.
Timo Stomberg is pursuing his PhD at the Institute of Geodesy and Geoinformation, University of Bonn, under the supervision of Prof. Dr.-Ing. Ribana Roscher. Throughout his involvement in the KI:STE project, he has authored two peer-reviewed articles as the lead author and collaborated on four other peer-reviewed publications. He has showcased his research findings at three conferences.
Model Error Correction - Kaveh Patakchi Yousefi
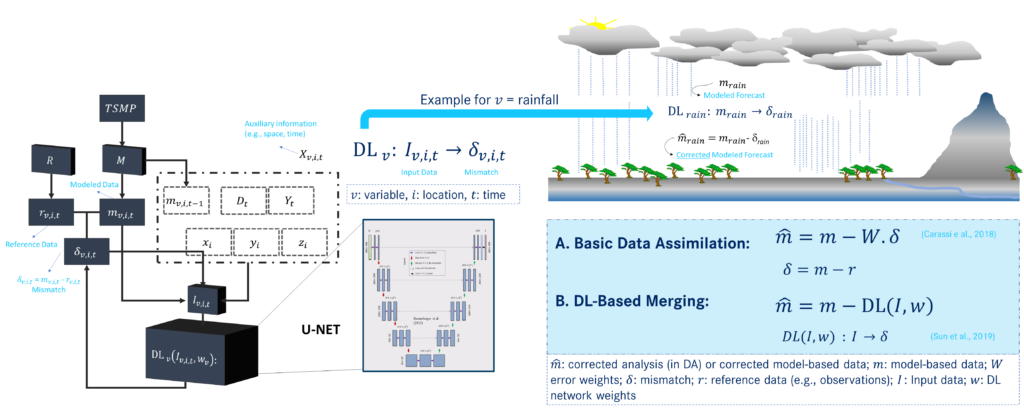
Hydrometeorological modelling relies on correcting precipitation data from numerical weather prediction models. Precipitation impacts energy and water balances in terrestrial systems, affecting hydrological processes and forecast accuracy. A novel deep learning-driven method called U-Net was used to improve atmospheric simulations by learning and correcting these mismatches independently of statistical assumptions inherent in basic data assimilation scheme. The U-Net network was trained on model “error” using only model-based atmospheric data as inputs. In this paper, the method was applied to two atmospheric parameters: surface pressure and precipitation.
Furthermore, in another study, the hydrological impact of various precipitation datasets was evaluated, including model-based short-term forecasts, near real-time satellite-based observations, and DL-based corrected precipitation. This research contributed to advancing our understanding of the role of precipitation data in hydrological forecasting and supporting informed decision-making in water resource management.
On the left, how DL network is trained to learn the mismatch δv,i,t using Iv,i,t as input data, which consists of the model output and corresponding mismatch and additional auxiliary information Xv,i,t. On the right, application of DL-based merging framework within integrated hydrological modeling and how DL (I, w) output can replace the statistical assumptions involved in calculating the error weight W in basic data assimilation
Kaveh Patakchi Yousefi is pursuing his PhD in institute of bio- and geociences in Jülich research center and University of Bonn, under the supervision of Prof. Dr. Stefan Kollet. Throughout his involvement in the KI:STE project, he has authored a peer-reviewed article, and he is actively engaged in the preparation of two publications as the lead author. So far, his research has been showcased at three international conferences.
Landcover and Crop Classification - Ankit Patnala
The KISTE project is driven by a core vision to explore the application of machine learning in Earth Science. Our team focused on investigating relationship between plant condition and air quality using existing self-supervised techniques i.e. to learn without labels. Recognizing the limitations of these techniques in detecting vegetation details and changes over time, we narrowed our focus to mapping crops from Earth Observation (EO) imagery.
Contrastive learning, a self-supervised learning method, has emerged as a superior approach for natural images. Drawing inspiration from it, our earlier work concentrated on developing an approach to efficiently apply contrastive learning to remote sensing images. Contrastive methods relies on contrastive losses and meaningful transformations. The exisitng methods developed for natural images such as in Imagenet, uses color jittering and grayscaling as one of the important transformation. The naive extension of color jittering and grayscaling to multiple channels of multispectral Sentinel2 image is physically insignificant. However, these channels contain vital information about the Earth’s surface, such as NIR reflections that aid in identifying vegetation states. Our research focused on developing a meaningful alternative transformation. Our research focused on developing atmospheric transformation, a transformation method based on well established atmpspheric correction method. We interpolated between atmospheric corrected and uncorrected images to obtain multiple views of the same image. In principle, this methods can be extended to all the channels of the multi-spectral image but we restricted our anaysis only on 4 channels i.e. NIR channel along with RGB channels. Further details can be found in our paper published in IEEE GRSL.
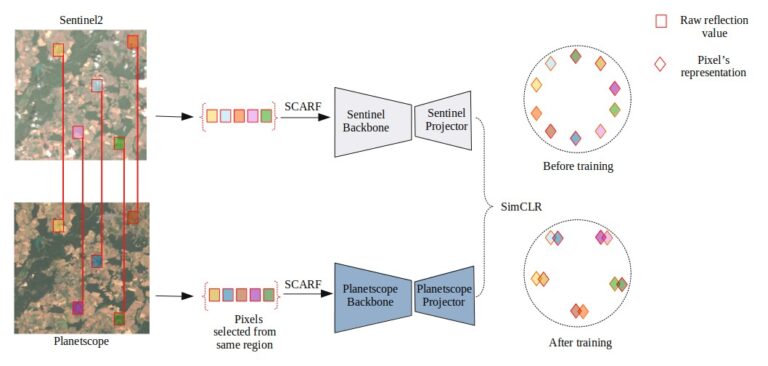
The subsequent task, aligning with our primary goal of crop mapping, involves extending the concept of contrastive learning to crops. Crops are typically analyzed with the temporal signature of different channels. Crop data are associated either with a field parcel or set of pixels from the same field parcel. The task of developing a meaningful transformation for pixels is non-trivial, and rather than relying solely on transformations, we employed multiple sources, specifically reflections measured by publicly available Sentinel2 and commercial Planetscope satellite missions. We designed a setup for obtaining representation using multi-modal contrastive learning and defined how to use the obtained representation to enhance crop mapping. Our self-supervised learning strategy involves aligning the spatial components of both satellite missions. The preprint of our work is currently available for further reference.
Multi-modal contrastive learning using SimCLR loss. The left selected pixels in red boxes show the corresponding data pair selected for pre-training. SCARF is the feature transformation applied on these data samples. On the right side, it shows how the alignment and uniformity is learnt while optimizing SimCLR loss.
Ankit Patnala is working as a PhD student at Forschungszentrum Juelich under the supervision of Prof. Martin Schultz. His work conducted in the scope of the KISTE project has been presented through a peer-reviewed journal publication and various contributions to conferences and workshops. He is a member of the HDS-LEE graduate school.
Shallow Landslides - Ann-Kathrin Edrich
Landslides endanger people and infrastructure worldwide. With the increasing availability of open-access (geo)data and increasing computational power, Machine Learning has gained increasing importance for determining the spatio-temporal susceptibility to landslide occurrence.
The Random Forest algorithm is one of the most established Machine Learning algorithms and has been used extensively for almost two decades. In the scope of the project conducted at the [Chair of Methods for Model-based Development in Computational Engineering](https://www.mbd.rwth-aachen.de/) at RWTH Aachen University, the Python-based susceptibility and hazard mapping framework [SHIRE]( https://doi.org/10.6084/m9.figshare.24339643) has been developed. SHIRE facilitates future application of Random Forest for landslide susceptibility assessment by providing generic yet flexible implementations for the individual steps of the susceptibility assessment process.
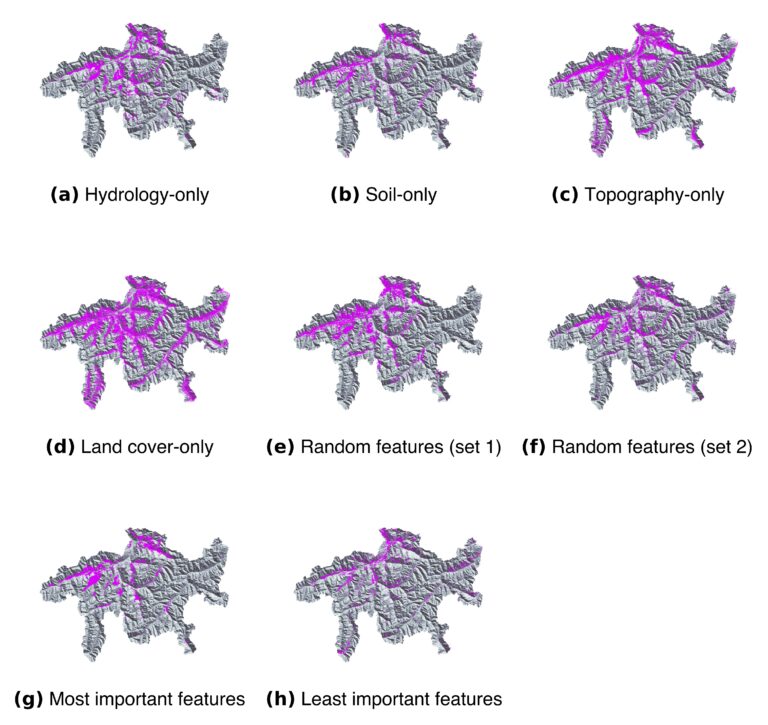
We investigated the sensitivity of the susceptibility assessment to training dataset compilation using SHIRE in terms of (1) class imbalance, (2) feature selection and combination and (3) representativeness. Using a test case of rainfall-triggered shallow landslides in the Swiss canton Grisons, we generated various susceptibility maps demonstrating the non-negligible influence of the careful training dataset composition. Figure 1 shows the impact of one-sided feature selection of only a single environmental domain as well as the influence of the varying combination of random features in the RF-based susceptibility assessment. The results have been presented in [Edrich et al. (2024)]( https://doi.org/10.1007/s11069-024-06563-8). Furthermore, we developed a novel methodology for generating RF-based temporal landslide hazard predictions which will also be presented in an upcoming publication.
Overall, our contribution in the KISTE project resulted in developing a concept of flexible and modular approach to ML-based landslide susceptibility, and an implementation of our methodology as an open-source software for future applications, as well as scientific publications in open access formats.
Landslide susceptibility in the Swiss canton Grisons when training the Random Forest using different feature subsets. (a) Only hydrological features, (a) Only hydrological features, (b) Only soil-related features, (c) Only topographical features, (d) Only land cover features, (e) Randomly sampled features across all environmental domains (set 1), (f) Randomly sampled features across all environmental domains (set 2), (g) Only the most important features according to feature importance assessment, (h) Only the least important features according to feature importance assessment, This figure has been published in [Edrich et al. (2024)]( https://doi.org/10.1007/s11069-024-06563-8)